The high-quality training (audio, corpus) data is crucial to use more accurate and faster data to train your machine learning models.
With highly trained experts dedicated to collecting high-quality data and years of experiences in participating in various projects, Adsound provides our domestic and overseas partners with customized AI training audio/corpus data collection services.
With our cloud platform, large audio and corpus data can be quickly collected and it undergoes stringent data validation by highly trained professionals to meet the diverse needs of the most demanding customers.
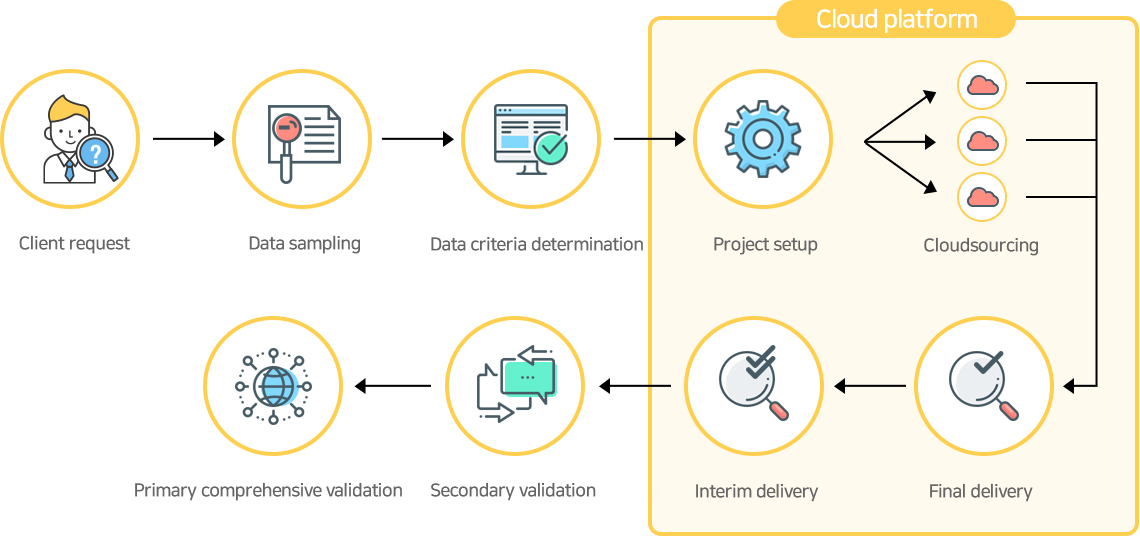
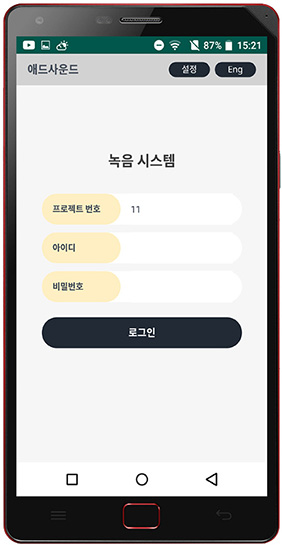
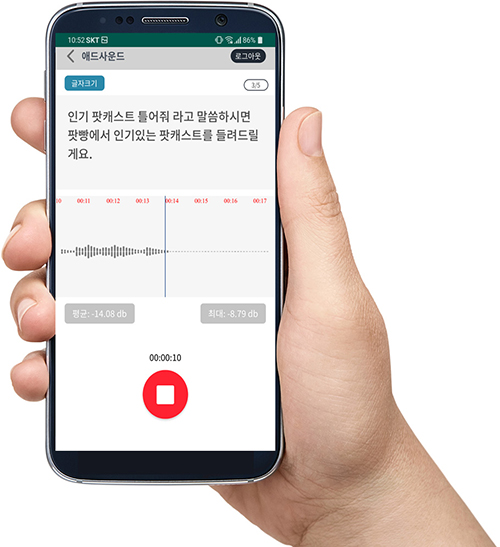
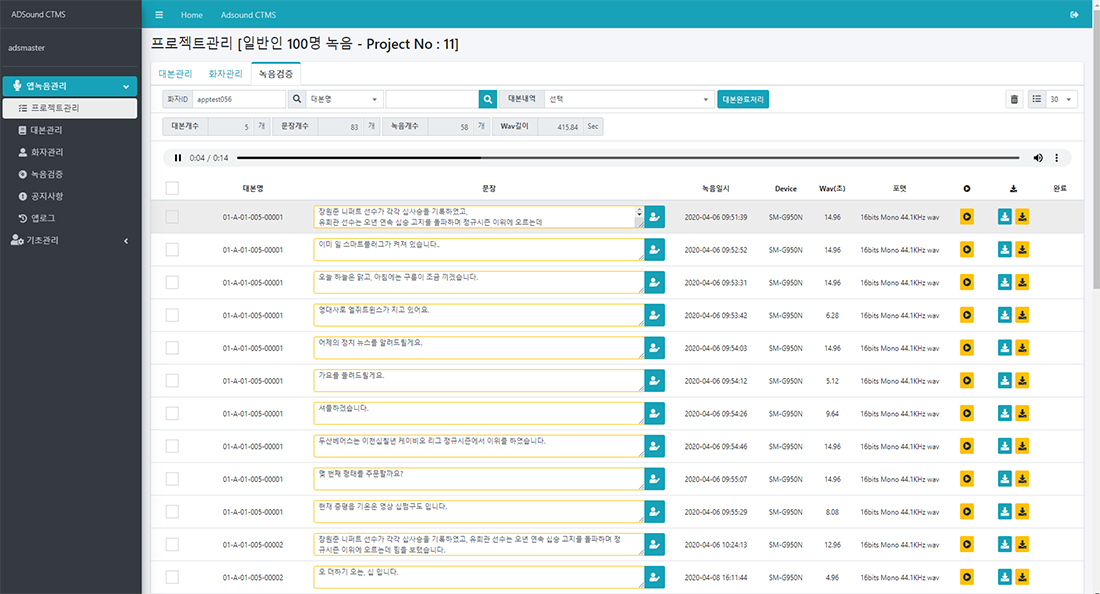
Project process flow (Cloud platform)
Cloud platform tailored to collect large datasets
Our online network-based cloud platform provides a large group of users with easy access to fast and efficient registration,
collection and management of large volume datasets under various conditions.
Solution team and system management
Our dedicated solution teams and excellent system management can ensure a faster response to constantly changing conditions as well as stable operation of required systems.
Experience with know-hows on various projects
Our extensive experience and know-hows are a unique property that allowed use to be recognized by our clients for faster and more accurate results, including data collection to complement varying environment: indoor, outdoor and mobile devices.
Highly trained and experienced experts
With 20 years of experience, we provide systematic training programs to our experienced team of experts that will ensure large volume data management and fast delivery.
PORTFOLIO
NAVER collected and delivered Korean speech recognition data of 2,000 ordinary men and women for smartphones
Google collected and delivered Korean voice synthesis data of voice actors (overseas)
NAVER collected and delivered speech recognition data of 200 ordinary men and women for smartphones in mobile environments
Sunflare collected and delivered speech recognition data of spoken language of ordinary men and women (overseas)
SKT MOS Test collected and delivered speech recognition data of 300 female and male elementary students
Samsung Robot TTS collected and delivered Korean voice synthesis data of voice actors
Sunflare collected and delivered speech recognition data of 1,800 ordinary men and women in different situations (overseas)
KT AI Speaker collected and delivered Korean voice synthesis data of voice actors
SKT AI Speaker collected and delivered Korean voice synthesis data of voice actors
Samsung AI voice assistant collected and delivered voice synthesis data of voice actors
Selvas AI collected and delivered voice synthesis data of voice actresses
Sunflare collected and delivered speech recognition data of 4,095 ordinary men and women in different situations (overseas)
Samsung collected and delivered 100-hour AI voice synthesis data of voice actors
Others collected and delivered voice command recognition data of 1,000 ordinary men and women for smartphones
Others collected and delivered speech recognition data of 400 adolescents for English learning
Others collected and delivered speech recognition data of 400 ordinary men and women of different regions and ages